图像先验帮助卷积神经网络利用少量信息训练
原文来自 How To Perform Image Restoration Absolutely Dataset Free
一般来讲,我们利用深度学习的模型来解决一些问题,都需要大量的数据集。但是在某些情况下,只需要一张图片就可以训练好模型,这里讲的是图片先验如何解决单张图片训练过拟合的问题。
这个文章讲的是Deep Image Prior 是CVPR2018的文章,这篇文章阐述了,CNN这种网络结构可以从少量图像中的信息,获得先验知识(prior)。这种先验知识可以帮助CNN网络结构解决图像恢复的一些问题。包括去噪,超分辨,in-painting, 和一些其他的任务。
这篇文章主要讲述三个点:
1. 图像恢复算法的一个概述
2. Deep Image Prior这篇文章的阐述,看他如何运用在图像恢复的任务中,这些原理又是什么。
3. 执行一些去噪的例子,展现一下这个方法的效果。
图像恢复
图像去噪

去噪即是,去除掉图像的一些噪声。有的是采集时探测器的噪声,比如泊松噪声;有的是高斯噪声,椒盐噪声等等。
图像超分辨

超分辨就是将一张低分辨率的图片,比如100*100大小的分辨率。变成一张高分辨率200*200的图片。这和光学上的分辨率有所区别,光学上一般考虑的物理上的含义,即分辨能力的大小。比如是否可以看清楚10nm的物体,假如原来看不到10nm的东西,用了某个物理方法可以看到10nm的,甚至更小的东西。那么这个物理方法就是光学上或者物理上的超分辨方法。计算机里面,一般是保持原有图像信息的情况下,放大图片的大小,保持原有的细节,不会使得图像模糊。
图像去污点 In-painting

图像去污就是去除掉图像上不想要的内容,一般是有遮挡的东西,或者信息被破坏,如上图所示。
上面就是简单介绍一下图像恢复言解决的问题,都是开胃小菜,现在来正餐,看看这篇论文提出的惊艳idea。
Deep Image Prior
什么是图片先验

图片先验一般是指我们可以知道其他的信息来辅助了解图片不包含的信息。比如上述图片中,左图是一张模糊的人脸图片如果我们是作画的人,要给这张图片加上一些细节,那么我们是可以根据自身了解到的人脸特征,给这张图加上一些细节。
学习到先验和特定的先验两种方法
Learned Prior:

通过清晰图片和噪声图片的数据对,对神经网络大量的训练,我们可以将图片的噪声去掉。那么这个神经网络就是学到了数据对的先验信息。这就是Leaned Prior。
explicit prior or handcrafted prior:

如上图所示,如果我们有一张模糊的图片 X^或者叫$x^{hat}$ ,我们想创造出一张图$X^{*}$,将它优化成为左边图$X$中的样子。
下面就来讲一下如何实现:
我们首先介绍两个计算方法,(1)计算图片的接近程度(closeness):$ E(x,x^{hat})$,我们可以用L2 norm 或者L1 norm的方法来计算清晰图片和模糊图片之间像素点上的差异。(2)计算图片的不自然程度(unnaturalness/unclearness):$R(X)$, $X$就是清晰图片。
之后我们通过计算最大似然的方法来确定目标函数,得到我们想要的$X^*$:
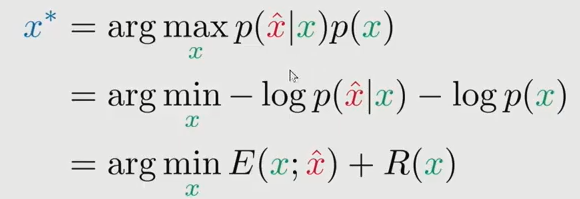
| 从上图可以看出,似然函数$-log\,p(x^{hat} | x)$ 就是用closeness的计算方法来表示,先验$-log\,p(x)$就是用$R(x)$来表示。所以先验就相当于一个正则项,如果没有这项,那么我们的目标函数优化最后的结果就是使得迭代图片$x$不断靠近噪声图片$x^{hat}$ 然后得到的就是一张噪声图片。加上先验图片$R(x)$这一项,就不会overfit, 使得目标函数对图片x有一定的平滑效果。 |
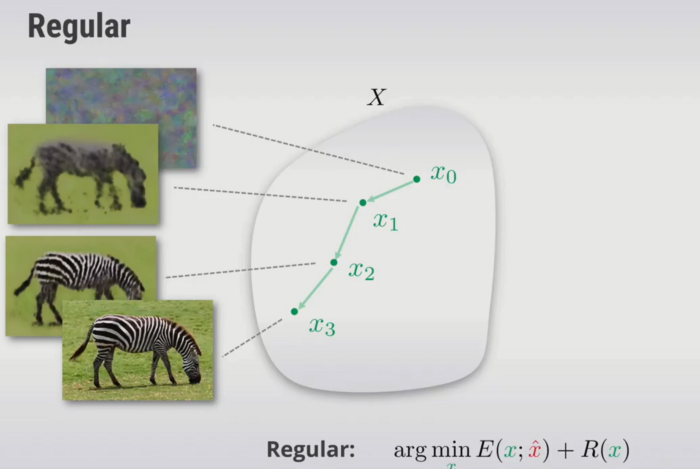
网络结构如何定义先验

我们的网络一般是把上述公式当作目标函数
传统的方法是用梯度下降的方式,初始化x之后,再反向更新模型参数,不断地迭代x,使得目标函数最终收敛。
这里有什么不同呢?可以先嵌套一层,定义每个输出的图片$x$都是一个函数输出的结果。 \(x = g(\theta)\) 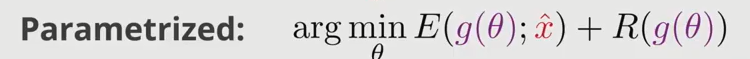
这样,我们就将要更新的数据变换到了另外一个空间,和上述相比,迭代如下所示,我们将图片空间的更新变为了参数空间的更新:
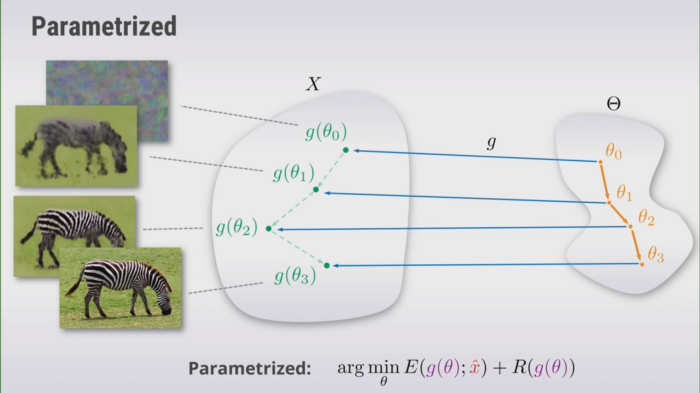
转换成参数空间的理由
为什么要这么做?将优化图片空间的任务转换为有参数空间的任务有什么不同?
实际上更新参数的过程就是找到一张natural image的过程,所以函数$ g(.)$ 可以被视为一个超参数,可以调整它以突出显示我们想要获得的图像, 即“自然”图像。所以函数$g(\theta)$实际上就是一种先验。(这里过度的不是很自然,可以去看原文)。那么我们就只需要优化第一项,不需要考虑先验项:
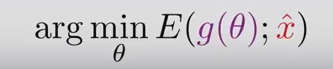
一般来说,我们会定义一个神经网络,比如说UNet, Resnet,然后将$\theta$作为网络的参数。所以我们将公式改写为如下的方式:
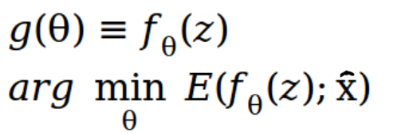
其中$z$就是随机输入的图片,可以是噪点,也可以是meshgrid等图片。$\theta $ 就是随机初始化的权重,之后通过梯度下降的方式优化,得到输出图片。
Implementation of Deep Image Prior in PyTorch
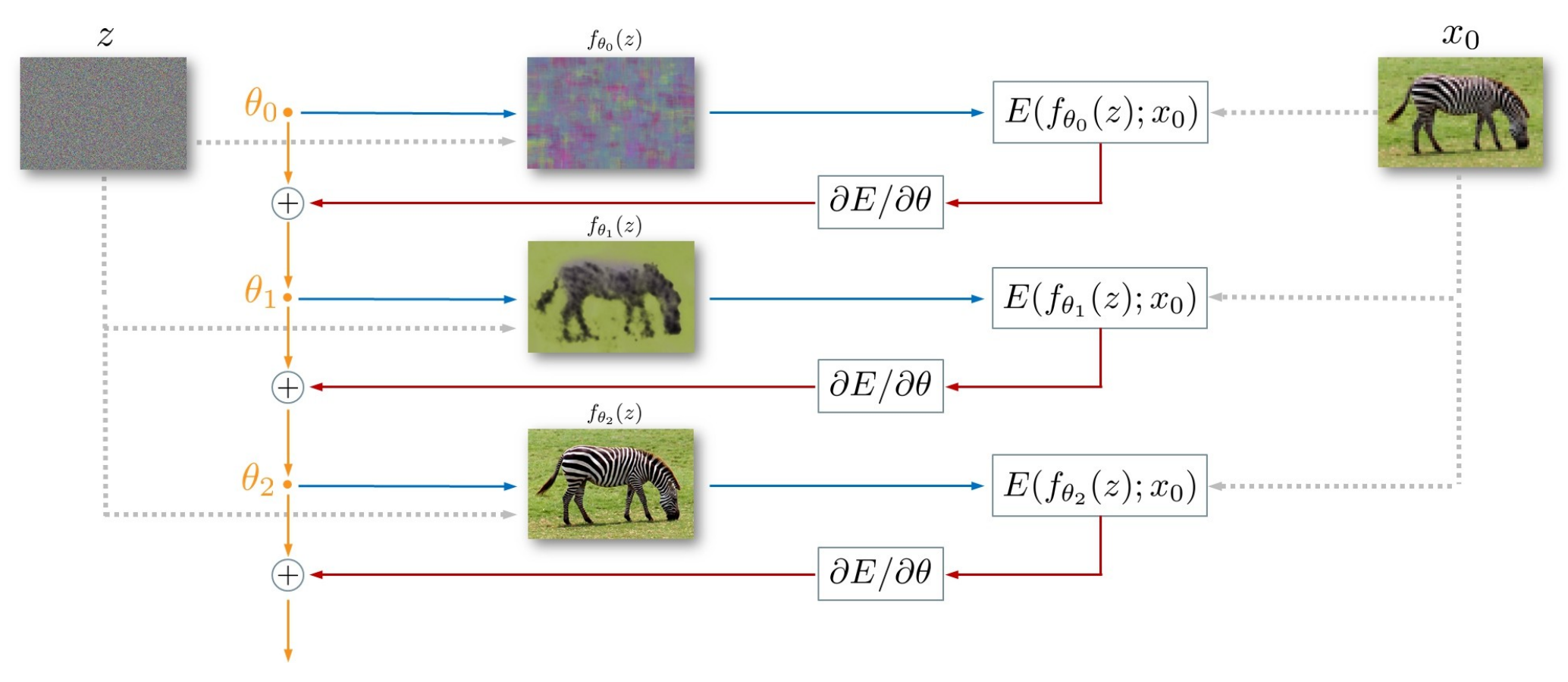
- 首先人工设计一个网络架构$f_\theta$ ,将其随机初始化。
- 将随机编码$z$ (如上图所示,可以是噪声的输入,也可以换为meshgrid)作为网络的输入,需要注意两点:第1是
在整个过程中是不变的;第2是
目标函数就是$min x-x_0 \,=\,min f_{\theta}(z)-x_0 $ ,这里我们让网络的输出 与degraded image
尽量接近。是的,你没看错,是与待修复/超分/复原/去噪的图片尽量接近。
- 采用如Adam方法训练。你可能会有疑问,那训练出来的网络输出不应该是degraded image吗?答案是:没错,如果把网络训练至稳定或者收敛,网络就会输出和degraded image一模一样的图像。
- 所以我们在训练到一半时打断训练,网络依旧输入随机编码
后续的一些操作:
https://zhuanlan.zhihu.com/p/242222614